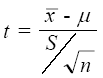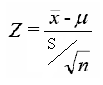Dentro del estudio de la inferencia estadística, se describe como se puede tomar una muestra aleatoria y a partir de esta muestra estimar el valor de un parámetro poblacional en la cual se puede emplear el método de muestreoy el teorema del valor central lo que permite explicar como a partir de una muestra se puede inferir algo acerca de una población, lo cual nos lleva a definir y elaborar una distribución de muestreo de medias muestrales que nos permite explicar el teorema del limite central y utilizar este teorema para encontrar las probabilidades de obtener las distintas medias maestrales de una población.
Paso 1: Plantear la hipótesis nula Ho y la hipótesis alternativa H1.
La hipótesis nula (Ho) se refiere siempre a un valor especificado del parámetro de población, no a una estadística de muestra. La letra H significa hipótesis y el subíndice cero no hay diferencia. Por lo general hay un "no" en la hipótesis nula que indica que "no hay cambio" Podemos rechazar o aceptar Ho.
La hipótesis nula es una afirmación que no se rechaza a menos que los datos muestrales proporcionen evidencia convincente de que es falsa. El planteamiento de la hipótesis nula siempre contiene un signo de igualdad con respecto al valor especificado del parámetro.
La hipótesis alternativa (H1) es cualquier hipótesis que difiera de la hipótesis nula. Es una afirmación que se acepta si los datos maestrales proporcionan evidencia suficiente de que la hipótesis nula es falsa. Se le conoce también como la hipótesis de investigación. El planteamiento de la hipótesis alternativa nunca contiene un signo de igualdad con respecto al valor especificado del parámetro.
Paso 2: Seleccionar el nivel de significancia.
Nivel de significacia: Probabilidad de rechazar la hipótesis nula cuando es verdadera. Se le denota mediante la letra griega α, tambiιn es denominada como nivel de riesgo, este termino es mas adecuado ya que se corre el riesgo de rechazar la hipótesis nula, cuando en realidad es verdadera. Este nivel esta bajo el control de la persona que realiza la prueba.
Si suponemos que la hipótesis planteada es verdadera, entonces, el nivel de significación indicará la probabilidad de no aceptarla, es decir, estén fuera de área de aceptación. El nivel de confianza (1-α), indica la probabilidad de aceptar la hipótesis planteada, cuando es verdadera en la población.
La distribución de muestreo de la estadística de prueba se divide en dos regiones, una región de rechazo (conocida como región crítica) y una región de no rechazo (aceptación). Si la estadística de prueba cae dentro de la región de aceptación, no se puede rechazar la hipótesis nula.
La región de rechazo puede considerarse como el conjunto de valores de la estadística de prueba que no tienen posibilidad de presentarse si la hipótesis nula es verdadera. Por otro lado, estos valores no son tan improbables de presentarse si la hipótesis nula es falsa. El valor crítico separa la región de no rechazo de la de rechazo.
Tipos de errores
Cualquiera sea la decisión tomada a partir de una prueba de hipótesis, ya sea de aceptación de la Ho o de la Ha, puede incurrirse en error:
Un error tipo I se presenta si la hipótesis nula Ho es rechazada cuando es verdadera y debía ser aceptada. La probabilidad de cometer un error tipo I se denomina con la letra alfa α.
Un error tipo II, se denota con la letra griega β se presenta si la hipótesis nula es aceptada cuando de hecho es falsa y debía ser rechazada.
En cualquiera de los dos casos se comete un error al tomar una decisión equivocada.
En la siguiente tabla se muestran las decisiones que pueden tomar el investigador y las consecuencias posibles.
Tipos de prueba
a) Prueba bilateral o de dos extremos: la hipótesis planteada se formula con la igualdad
Ejemplo
H0 : µ = 200
H1 : µ ≠ 200
b) Pruebas unilateral o de un extremo: la hipótesis planteada se formula con ≥ o ≤
H0 : µ ≥ 200 H0 : µ ≤ 200
H1 : µ < 200 H1 : µ > 200
En las pruebas de hipótesis para la media (μ), cuando se conoce la desviación estándar (σ) poblacional, o cuando el valor de la muestra es grande (30 o más), el valor estadístico de prueba es z y se determina a partir de:
El valor estadístico z, para muestra grande y desviación estándar poblacional desconocida se determina por la ecuación:
En la prueba para una media poblacional con muestra pequeña y desviación estándar poblacional desconocida se utiliza el valor estadístico t.
Son los Puntos más importantes que debemos tener en cuenta.
El Miércoles 8 examen práctico.





c; multiplicándolas por - 1 se transforman en inecuaciones de la forma - ax - by
- c y estamos en el caso anterior